Was Menschen wirklich speichern: eine Datenstudie (2026)
studies
Was Menschen wirklich speichern: eine Datenstudie (2026)
Wir haben die ersten 119 auf SavedThat gespeicherten Videos analysiert. Plattform-Mix, Dauer-Verteilung, Suchverhalten und was frühe Nutzer uns über Save-Workflows erzählen.
SavedThat team···9 min read
7-day free trial · cancel anytime
Die meisten «Was Menschen speichern»-Artikel sind Vibes. Wir haben das echte Query gezogen.
Das ist eine ehrliche Datenstudie der ersten 119 auf SavedThat gespeicherten Videos von 43 frühen Nutzern und der 202 Suchen, die diese Nutzer darüber gefahren haben. Kleine Stichprobe, transparente Einschränkungen. Unten: was die Zahlen wirklich darüber sagen, wie Menschen 2026 Videos speichern und wiederfinden.
Der volle Breakdown steht am Ende des Posts. Die drei Findings, die uns überrascht haben:
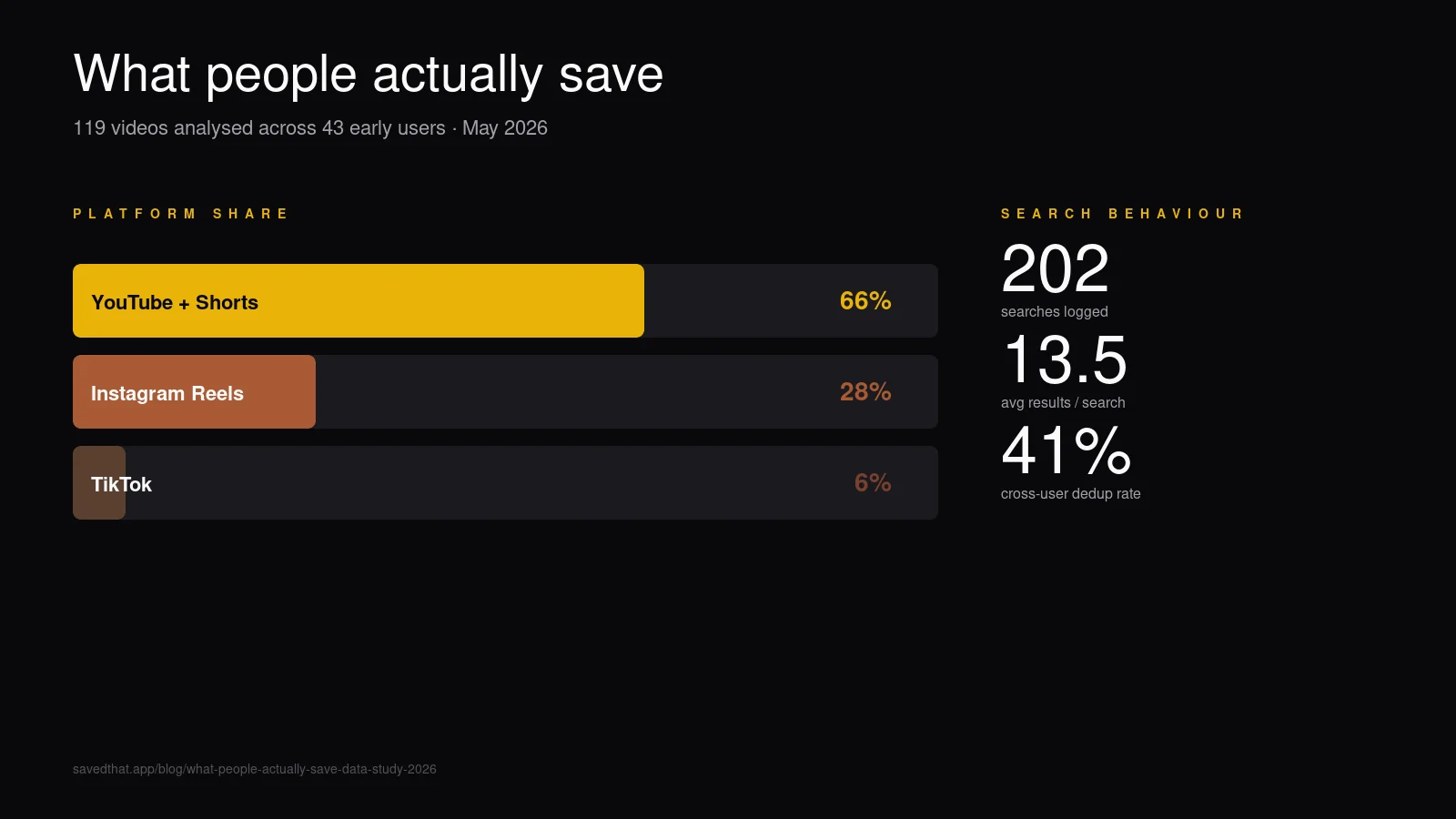
YouTube dominiert nicht nach Anzahl, sondern nach Content-Dichte. Zwei Drittel der gespeicherten Videos sind YouTube, aber sie machen 30+× das gesprochene-Content-Volumen von Instagram + TikTok zusammen aus.
16% der Suchen liefern null Ergebnisse. Entweder hat der Nutzer das falsche Video gespeichert oder vor dem Speichern des richtigen Videos gesucht. Beides sind Produkt-Signale.
Cross-User-Deduplikation greift schon in diesem Maßstab. 158 Lesezeichen zeigen auf 112 einzigartige Videos — etwa 1 von 7 Saves ist ein Duplikat des bereits indexierten Transkripts eines anderen.
Analysierte Videos: 119 (Status ready zum 11. Mai 2026)
Lesezeichen: 158 (mehrere Nutzer können dasselbe Video speichern, dedupliziert in unserem Cross-User-Content-Store)
Einzigartige Nutzer: 43 von 43 registrierten Accounts
Geloggte Suchen: 202 von 15 Nutzern
Klein. Caveat vorab. Wir laufen das neu, wenn der Korpus 1.000 erreicht, und nochmal bei 10.000. Muster bei 100 sind rauschend, aber interessant, weil sie aktuell sind und davon geformt, wer sich für ein frühes Produkt registriert hat.
Zwei Drittel YouTube bestätigen, was das Marketing jedes Bookmark-Tools annimmt: Langform-Video-Saves dominieren weiterhin den Prosumer-Use-Case. Was uns überrascht hat, war die Lücke innerhalb YouTubes selbst — durchschnittlich 30-minütige Videos bedeuten, dass unsere frühen Nutzer Podcasts, Interviews und Konferenzvorträge speichern, nicht Shorts. Vergleich mit YouTubes offizieller mittlerer Upload-Dauer — das Median-Video auf der Plattform ist weit kürzer, also ist was Menschen speichern deutlich Richtung längerer Inhalte verzerrt.
Instagram liegt mit 28% auf Platz zwei — das sind Kurzform-Reels mit durchschnittlich unter einer Minute. Ein Reel zu speichern und eine 90-minütige Lex-Fridman-Episode zu speichern sind offensichtlich verschiedene Jobs, auch wenn beide in derselben Bibliothek landen.
TikTok ist Dritter mit 6%, hauptsächlich weil die Kohorte älter skewt (Gründer, Researcher, Produkt-Leute). Das rebalanciert sich schnell, sobald SavedThats Publikum breiter wird.
YouTube-Saves tragen 30× mehr gesprochenes Content-Volumen bei als Instagram + TikTok zusammen. Die Kategorie sieht nach Anzahl ausgewogen aus und ist nach dem, was tatsächlich in den Videos steckt, stark schief. Das zählt für Transkriptsuche-Workflows: die meisten Suchanfragen liefern YouTube-Treffer nicht, weil YouTube in Saves überrepräsentiert ist, sondern weil YouTube-Videos viel mehr Text zum Matchen enthalten.
Die 119 Videos sortieren sich in zwei klare Höcker mit einer Lücke:
Dauer-Bucket
Videos
% gesamt
Unter 1 Minute
38
32%
1–10 Minuten
28
24%
10–30 Minuten
23
19%
30–60 Minuten
13
11%
Über 1 Stunde
11
9%
Der 32%-unter-einer-Minute-Höcker sind überwältigend Reels und TikToks — schnelle Saves von Rezepten, Demos, Witzen. Die oberen Höcker mit 19% + 11% + 9% (43 Videos, 36%) sind Langform-YouTube-Content, wo die Informationsdichte pro Video das Speichern rechtfertigt.
Der mittlere 1–10-Minuten-Bucket (24%) ist der seltsamste — YouTube-Tutorials, kurze Lex-Fridman-Clips, Podcast-Highlights. Hier ging «Watch Later» historisch zum Sterben, weil die Videos zu lang für casual Scroll-Schauen und zu kurz sind, um sich's wert zu fühlen, sie zu blocken. Transkriptsuche rettet genau diesen Bucket: bei 5 Minuten pro Video würdest du nie wieder schauen, um ein Zitat zu finden — also ist Suche-nach-Inhalt der einzige Retrieval-Pfad.
Wir haben 202 Suchen von 15 der 43 Nutzer geloggt. Drei Zahlen stechen heraus:
Ø Ergebnisse pro Suche: 13,5. Eine vernünftige Dichte — semantische Suche ist standardmäßig über-eifrig; wir deckeln die Ergebnisliste auf 20, und der Durchschnitt sitzt komfortabel darunter.
Null-Ergebnis-Suchen: 33 (16%). Eine von sechs Suchen liefert nichts.
Suchende Nutzer / Gesamt: 15 / 43 (35%). Nur ein Drittel der registrierten Nutzer hat bisher gesucht.
Die 16%-Null-Ergebnis-Quote ist die interessanteste Metrik. Drei Diagnosen, warum:
Falscher Korpus. Nutzer hat nach einem Zitat aus einem Video gesucht, das er noch gar nicht gespeichert hatte. Häufig in der ersten Nutzungswoche. Der Fix ist produkt-seitig: zeig einen «speicher zuerst ein Video»-Empty-State, wenn ein Nutzer mit weniger als 3 Saves suchen will.
Semantik-Verfehler. Die Query-Sprache war zu weit weg von der Transkript-Sprache, und Reciprocal Rank Fusion hat die Lücke nicht überbrückt. Sehen wir am meisten, wenn Nutzer auf Russisch gegen eine komplett englische Bibliothek suchen.
Echt schlechte Transkripte. Eine Handvoll Videos mit Auto-Captions, die den gesprochenen Inhalt nicht gut abdeckten. Suche kann nicht finden, was nicht indexiert war.
Diese drei Ursachen splitten sich in unserem manuellen Review von 20 Null-Ergebnis-Suchen ungefähr gleich auf. Jede davon ist ein Produkt-Fix; keine ist ein Suchmaschinen-Fix.
Die 35%-Such-Engagement-Quote ist ehrlich und wahrscheinlich typisch für ein Tool, dessen Wert mit Bibliotheksgröße wächst — bei weniger als 5 Saves pro Nutzer gibt es nichts Sinnvolles, worüber man suchen könnte. Wir laufen das neu, sobald Accounts im Schnitt 20 Saves überschreiten, um zu sehen, ob Engagement konvergiert.
158 Lesezeichen gegen 112 einzigartige Content-Stücke heißt, etwa 41% der Nutzer haben mindestens einmal ein Video gespeichert, das jemand anders schon gespeichert hatte. Das meist-gespeicherte einzelne Video hat 11 Lesezeichen über Nutzer hinweg. Ø Lesezeichen pro Content-Stück: 1,41.
Das ist ein direktes ökonomisches Signal. Jeder Duplikat-Save ist ein Transkript-Fetch + OpenAI-Embedding-Cost, den wir nicht bezahlen (Instagram/TikTok werden via Supadata bezahlt; YouTube ist gratis, aber compute-billable). Bei 41% Dedup-Hit-Quote in einem 43-Nutzer-Korpus spart der Cross-User-Content-Store schon echtes Geld. Bei 1.000 Nutzern erwarten wir, dass die Quote Richtung 70%+ kriecht — die populärsten Videos konvergieren.
Die Produkt-Implikation: wenn ein neuer Nutzer ein populäres Video speichert, landet es in seiner Bibliothek in unter einer Sekunde mit null Credit-Kosten, weil Transkript und Embeddings schon existieren. Diese Erfahrung ist ein Moat — Konkurrenten mit Pro-Nutzer-Content-Stores können das nicht matchen.
Transkriptsuche ist ein Langform-Video-Feature. Die 30×-Content-Dichte-Lücke zwischen YouTube und Kurzform bedeutet, dass das technische Heavy Lifting auf der Langform-Seite stattfindet. Reel- und TikTok-Transkripte sind billig zu holen und zu durchsuchen; YouTube-Transkripte sind, wo Index-Volumen und Retrieval-Qualität sich auszahlen.
Der Mittel-Dauer-Bucket ist unbesetzt. 1–10-Minuten-Videos machen 24% der Saves aus und werden von existierenden Tools am schlechtesten bedient. YouTubes natives «Watch Later» behandelt sie wie 60-Minuten-Videos (vorbeiscrollen). Die Kurzform-Tools (Glasp) behandeln sie wie 60-Sekunden-Videos (konkrete Momente markieren). Keines passt. Ein Transkriptsuche-Tool, das den 1–10-Minuten-Bucket gut abbildet, gewinnt dieses Segment — und fast niemand optimiert dafür.
Cross-User-Dedup wird untervermarktet. Jedes Transkriptsuche-Tool außer SavedThat behandelt die Bibliothek jedes Nutzers als eigene Datenbank. Bei 100 Nutzern zählt das nicht. Bei 10.000 Nutzern ist es der Unterschied zwischen nachhaltiger Marge und OpenAI-Credits-Verbrennen auf Duplikat-Content. Wir erwarten, dass der Rest der Kategorie das in 12 Monaten kopiert.
Diese ganze Studie ist als re-runnable gedacht. Wir veröffentlichen Updates bei drei Meilensteinen:
1.000 analysierte Videos. Wahrscheinlich H2 2026. Wir erwarten, dass sich der Plattform-Mix abflacht (TikTok klettert, YouTube gibt Anteile ab) und die Dedup-Quote springt.
10.000 analysierte Videos. Wahrscheinlich 2027. Die Dauer-Bimodalität sollte sich verschärfen, und die Null-Ergebnis-Quote sollte fallen, sobald Content-Dichte mit Query-Breite mithält.
100.000 analysierte Videos. Irgendwann. Da sind wir noch nicht.
Wenn du im nächsten Snapshot sein willst, ist die Bibliothek, in die du speicherst, die, die wir zählen. Siehe Pricing oder Start kostenlos.
Alles andere im Post leitet sich aus dieser Tabelle ab. Wir veröffentlichen sie, damit jeder Anspruch oben gegen die Quelle prüfbar ist.
Metrik
Wert
Videos mit `status=ready` gesamt
119
Nutzer-Lesezeichen gesamt (videos.videos-Zeilen)
158
Einzigartiger Content (distinct video_content_id)
112
Registrierte Nutzer
43
Nutzer, die mindestens einmal gesucht haben
15
Geloggte Suchen gesamt
202
Ø Ergebnisse pro Suche
13,5
Null-Ergebnis-Suchen
33 (16%)
YouTube + Shorts (ready)
79
Instagram Reels (ready)
33
Snapshot genommen: 11. Mai 2026.
Frequently asked questions (2026)
Sind 119 Videos genug, um Schlüsse daraus zu ziehen?+
Nein — deshalb ist das als Snapshot gerahmt, nicht als Studie. Muster bei 100 Videos sind direktional interessant, statistisch aber dünn. Wir veröffentlichen die Methodik und exakten Zahlen, damit der nächste Snapshot bei 1.000 und 10.000 vergleichbar ist — nicht damit jemand beim Lesen Business-Entscheidungen auf einer 119-Zeilen-Stichprobe trifft.
Wurden Nutzer aus den Daten ausgeschlossen?+
Drei video_content-Zeilen im Status `failed` wurden ausgeschlossen (Transkript-Fetch ist über die Retry-Grenze hinaus gescheitert). Alle 43 registrierten Nutzer sind eingeschlossen, unabhängig von ihrer Save-Anzahl, inklusive der 28 Nutzer, die noch nicht gesucht haben. Wir haben keine Nutzer-Demografien ausgeschlossen — der Snapshot spiegelt jeden wider, der zum 11. Mai 2026 registriert war.
Wie wurde «gesprochenes Content-Volumen» berechnet?+
Anzahl Videos pro Plattform multipliziert mit Mittelwert-Dauer in Sekunden. Das approximiert das gesprochene Gesamt-Content, weil Transkript-Wortzahl linear mit Dauer für die meiste Sprache korreliert. Wir zählen keine stillen Segmente, Musik oder visuellen Content — nur die sprache-tragende Dauer.
Warum ist der Ø Lesezeichen pro Content (1,41) so niedrig?+
Cross-User-Dedup verstärkt sich mit Kohorten-Größe. Bei 43 Nutzern aus einem frühen Produkt-Launch haben die meisten Videos noch nur ein Lesezeichen. Mit wachsenden registrierten Nutzern akkumulieren die populärsten Videos Lesezeichen schneller, als neue Videos gespeichert werden, und der Durchschnitt steigt. Pocket erreichte im Maßstab 5–7× durchschnittliche Lesezeichen pro URL; wir erwarten eine ähnliche Bahn.
TikTok (ready)
7
Ø YouTube-Dauer
1.810 Sek (30:10)
Ø Reel-Dauer
56 Sek
Ø TikTok-Dauer
26 Sek
Am meisten gespeichertes einzelnes Video
11 Nutzer
Ø Lesezeichen pro Content-Stück
1,41
Cross-User-Dedup-Hit-Quote
~41%
Lasst ihr diese Studie im Maßstab neu laufen?+
Ja — bei 1.000 Videos, 10.000 Videos und 100.000 Videos. Jeder Meilenstein-Post behält dieselbe Methodik und Tabellenformat, damit Leser die Zahlen direkt diffen können. Abonniere den SavedThat-Blog-RSS oder folg den Gründern auf X für den nächsten Snapshot.
Kann ich die Rohdaten sehen?+
Nein — gespeicherte Videos und Suchanfragen sind private Nutzer-Daten und nicht exportierbar. Die Aggregat-Zahlen in diesem Post sind aus anonymisierten Counts berechnet; nichts in der veröffentlichten Tabelle lässt sich auf einen einzelnen Nutzer oder ein Video zurückführen. Wenn du die Methodik verifizieren willst, registrier dich für SavedThat und du siehst dieselben Query-Muster in deiner eigenen Bibliothek.