O que as pessoas realmente salvam: um estudo de dados (2026)
studies
O que as pessoas realmente salvam: um estudo de dados (2026)
Analisamos os primeiros 119 vídeos salvos no SavedThat. Mix de plataformas, distribuição de duração, comportamento de busca e o que os primeiros usuários nos contam sobre fluxos de vídeo salvo.
SavedThat team···11 min read
7-day free trial · cancel anytime
A maioria dos artigos «o que as pessoas salvam» é vibe. A gente puxou a consulta real.
Este é um estudo de dados honesto dos primeiros 119 vídeos salvos no SavedThat por 43 usuários early, e das 202 buscas que esses usuários rodaram. Amostra pequena, caveats transparentes. Abaixo: o que os números realmente dizem sobre como as pessoas salvam e reencontram vídeos em 2026.
O destrinche completo está no final do post. As três descobertas que nos surpreenderam:
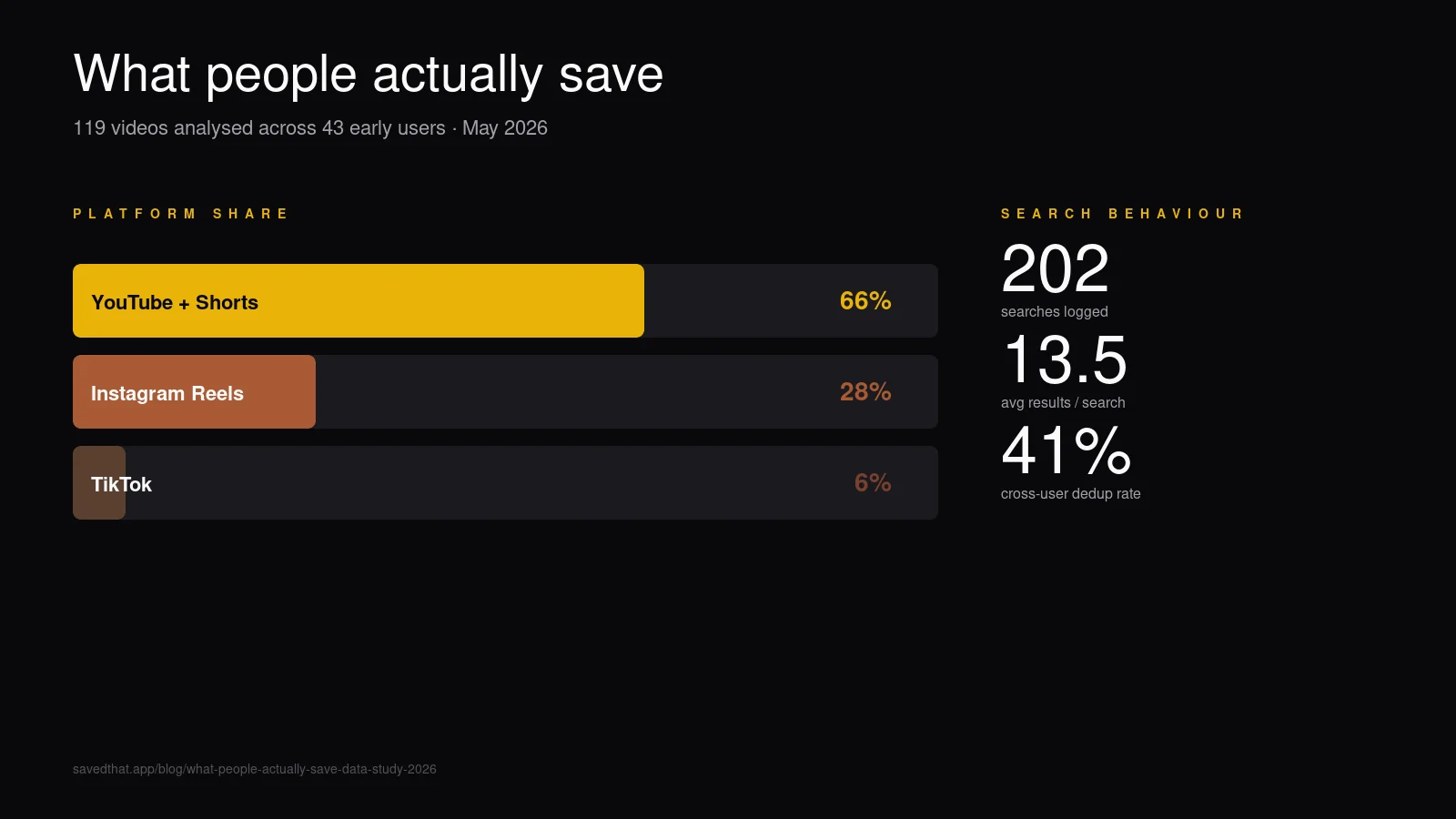
YouTube não domina por contagem, domina por densidade de conteúdo. Dois terços dos vídeos salvos são YouTube, mas representam 30+× o volume de conteúdo falado de Instagram + TikTok combinados.
16% das buscas retornam zero resultado. Ou o usuário salvou o vídeo errado, ou consultou antes de salvar o certo. Os dois são sinais de produto.
A deduplicação cross-user opera mesmo nessa escala. 158 favoritos apontam pra 112 vídeos únicos — cerca de 1 em 7 salvos é um duplicado de uma transcrição já indexada por outra pessoa.
Vídeos analisados: 119 (status ready em 11 de maio de 2026)
Favoritos: 158 (múltiplos usuários podem salvar o mesmo vídeo, deduplicado no nosso store de conteúdo cross-user)
Usuários únicos: 43 de 43 contas cadastradas
Buscas logadas: 202 por 15 usuários
Pequeno. Caveat assumido na frente. A gente vai rerodar quando o corpus bater 1.000 e de novo em 10.000. Padrões em 100 são barulhentos mas interessantes porque são atuais e moldados por quem realmente se cadastrou num produto em early-stage.
Dois terços YouTube confirma o que o marketing de toda ferramenta de favoritos pressupõe: salvos de vídeo long-form ainda dominam o caso prosumer. O que nos surpreendeu foi o gap dentro do próprio YouTube — vídeos em média de 30 minutos significam que nossos usuários early salvam podcasts, entrevistas e talks de conferência, não Shorts. Compara com a duração mediana oficial de upload do YouTube — o vídeo mediano na plataforma é muito mais curto, então o que as pessoas salvam está bastante enviesado pra conteúdo mais longo.
Instagram entra em segundo com 28% — são Reels de formato curto em média abaixo de um minuto. Salvar um Reel e salvar um episódio de 90 minutos do Lex Fridman são claramente jobs diferentes mesmo que os dois acabem na mesma biblioteca.
TikTok é terceiro com 6%, principalmente porque a cohort enviesa mais velha (founders, pesquisadoras, gente de produto). Isso vai se reequilibrar rápido conforme a audiência do SavedThat se amplia.
YouTube: 79 vídeos × 1.810 seg média = 143.000 segundos falados
Instagram: 33 vídeos × 56 seg média = 1.850 segundos falados
TikTok: 7 vídeos × 26 seg média = 180 segundos falados
Salvos do YouTube contribuem 30× mais volume de conteúdo falado que Instagram + TikTok combinados. A categoria parece equilibrada por contagem e é bem desbalanceada pelo que há de fato dentro dos vídeos. Isso importa pra fluxos de busca em transcrição: a maioria das consultas devolve hits do YouTube não porque o YouTube está super-representado nos salvos, mas porque vídeos do YouTube contêm vastamente mais texto pra dar match.
Os 119 vídeos se ordenam em duas corcovas claras com um vale:
Faixa de duração
Vídeos
% do total
Menos de 1 minuto
38
32%
1-10 minutos
28
24%
10-30 minutos
23
19%
30-60 minutos
13
11%
Mais de 1 hora
11
9%
A corcova 32% de menos-de-um-minuto é majoritariamente Reels e TikToks — salvos rápidos de receitas, demos, piadas. As corcovas superiores 19% + 11% + 9% (43 vídeos, 36%) são conteúdo long-form do YouTube onde a densidade de informação por vídeo justifica o salvar.
A faixa do meio 1-10 minutos (24%) é a mais estranha — tutoriais do YouTube, clipes curtos do Lex Fridman, highlights de podcast. É onde o «watch later» historicamente ia morrer porque os vídeos são longos demais pra scroll-watching casual e curtos demais pra valer agendar. A busca em transcrição salva especificamente essa faixa: com 5 minutos por vídeo, você nunca reassistiria pra achar uma citação, então busca-por-conteúdo é o único caminho de recuperação.
A gente logou 202 buscas por 15 dos 43 usuários. Três números se destacam:
Resultados médios por busca: 13,5. Densidade razoável — a busca semântica é over-eager por padrão; a gente capeia a lista em 20 e a média senta confortável abaixo.
Buscas de zero resultado: 33 (16%). Uma em seis buscas devolve nada.
Usuários que buscaram / total: 15 / 43 (35%). Só um terço dos cadastrados buscou até agora.
A taxa de 16% de zero-resultado é a métrica mais interessante. Três diagnósticos do porquê:
Corpus errado. Usuário buscou citação de vídeo que ainda não tinha salvado. Comum na primeira semana de uso. O conserto é do lado do produto: mostrar um empty state «salva um vídeo primeiro» quando um usuário com menos de 3 salvos consulta.
Erro semântico. O idioma da consulta estava longe demais do idioma da transcrição e a reciprocal rank fusion não fechou o gap. A gente vê isso principalmente quando usuários consultam em russo contra uma biblioteca toda em inglês.
Transcrições genuinamente ruins. Um punhado de vídeos com auto-legendas que não cobriram bem o conteúdo falado. Busca não consegue achar o que não foi indexado.
Essas três causas se dividem mais ou menos parelhas na revisão manual que a gente fez em 20 buscas de zero-resultado. Cada uma é fix de produto; nenhuma é fix do motor de busca.
A taxa de engajamento de busca de 35% é honesta e provavelmente típica pra uma ferramenta cujo valor se acumula com o tamanho da biblioteca — com menos de 5 salvos por usuário, não tem nada útil pra buscar. A gente vai rerodar isso quando as contas cruzarem 20 salvos em média pra ver se o engajamento converge.
158 favoritos contra 112 peças únicas de conteúdo significa que cerca de 41% dos usuários ao menos uma vez salvaram um vídeo que outra pessoa já tinha salvado. O vídeo único mais salvo tem 11 favoritos entre usuários. Favoritos médios por peça de conteúdo: 1,41.
Esse é um sinal econômico direto. Cada salvo duplicado é um fetch de transcrição + custo de embedding OpenAI que a gente não paga (Instagram/TikTok são pagos via Supadata; YouTube é grátis mas custa em compute). A 41% de taxa de hit dedup num corpus de 43 usuários, o store de conteúdo cross-user já está economizando dinheiro real. Em 1.000 usuários, a gente esperaria a taxa subir pra 70%+ — vídeos populares convergem.
A implicação de produto: quando um usuário novo salva um vídeo popular, ele aterrissa na biblioteca em menos de um segundo com zero custo de crédito, porque transcrição e embeddings já existem. Essa experiência é um moat — concorrentes com stores de conteúdo por-usuário não conseguem igualar.
Busca em transcrição é feature de vídeo long-form. O gap de 30× de densidade de conteúdo entre YouTube e formato curto significa que o peso técnico está no lado long-form. Transcrições de Reel e TikTok são baratas de puxar e buscar; transcrições do YouTube é onde o volume de índice e o trabalho de qualidade de recuperação compensa.
A faixa de duração média não tem dono. Vídeos de 1-10 minutos são 24% dos salvos e os menos servidos pelas ferramentas existentes. O «Watch Later» nativo do YouTube trata como vídeos de 60 minutos (passa scroll). Ferramentas de formato curto (Glasp) tratam como vídeos de 60 segundos (grifa momentos específicos). Nenhum encaixa. Uma ferramenta de busca em transcrição que serve bem a faixa 1-10 minutos ganha esse segmento, e quase ninguém está otimizando pra ela.
Dedup cross-user é sub-marketada. Toda ferramenta de busca em transcrição exceto SavedThat trata a biblioteca de cada usuário como banco próprio. Em 100 usuários isso não importa. Em 10.000 usuários, é a diferença entre margem sustentável e queimar crédito OpenAI em conteúdo duplicado. A gente espera o resto da categoria copiar nos próximos 12 meses.
Esse estudo inteiro é feito pra ser re-runável. A gente vai publicar updates em três marcos:
1.000 vídeos analisados. Provavelmente H2 2026. A gente espera o mix de plataformas achatar (TikTok subindo, YouTube cedendo share), e a taxa de dedup pular.
10.000 vídeos analisados. Provavelmente 2027. A bimodalidade de duração deve afiar, e a taxa de busca zero-resultado deve cair conforme a densidade de conteúdo alcança a amplitude das consultas.
100.000 vídeos analisados. Algum dia. A gente ainda não chegou.
Se quer estar no próximo snapshot, a biblioteca em que você salva é a que a gente conta. Vê pricing ou começa grátis.
Tudo mais neste post deriva desta tabela. A gente publica pra que qualquer afirmação acima seja verificável contra a fonte.
Métrica
Valor
Total de vídeos com `status=ready`
119
Total de favoritos de usuário (linhas videos.videos)
158
Conteúdo único (videos.video_content_id distinct)
112
Usuários cadastrados
43
Usuários que buscaram pelo menos uma vez
15
Total de buscas logadas
202
Resultados médios por busca
13,5
Buscas de zero resultado
33 (16%)
YouTube + Shorts (ready)
79
Reels do Instagram (ready)
Snapshot tirado: 11 de maio de 2026.
Frequently asked questions (2026)
119 vídeos é o bastante pra tirar conclusões?+
Não — por isso é enquadrado como snapshot, não estudo. Padrões em 100 vídeos são direcionalmente interessantes mas estatisticamente magros. A gente publica a metodologia e os números exatos pra que o próximo snapshot em 1.000 e 10.000 seja comparável, não pra que quem lê tome decisões de negócio numa amostra de 119 linhas.
Algum usuário foi excluído dos dados?+
Três linhas de video_content em status `failed` foram excluídas (o fetch de transcrição errou além do limite de retries). Todos os 43 usuários cadastrados estão incluídos independente do número de salvos, incluindo os 28 usuários que ainda não buscaram. A gente não excluiu nenhuma demografia de usuário — o snapshot reflete todo mundo cadastrado em 11 de maio de 2026.
Como o «volume de conteúdo falado» foi calculado?+
Contagem de vídeos por plataforma multiplicada pela duração média em segundos. Isso aproxima o conteúdo falado total porque a contagem de palavras da transcrição correlaciona linearmente com a duração pra maior parte da fala. A gente não conta segmentos silenciosos, música ou conteúdo visual — só a duração portadora de fala.
Por que a média de favoritos por conteúdo (1,41) é tão baixa?+
A dedup cross-user se compõe com o tamanho da cohort. Em 43 usuários amostrados de um lançamento early de produto, a maioria dos vídeos ainda tem só um favorito. Conforme os usuários cadastrados crescem, os vídeos mais populares acumulam favoritos mais rápido do que vídeos novos são salvos, e a média sobe. O Pocket alcançou 5-7× favoritos médios por URL em escala; a gente espera trajetória similar.
33
TikTok (ready)
7
Duração média YouTube
1.810 seg (30:10)
Duração média Reel
56 seg
Duração média TikTok
26 seg
Vídeo único mais favoritado
11 usuários
Favoritos médios por peça de conteúdo
1,41
Taxa de hit dedup cross-user
~41%
Vão rerodar esse estudo em escala?+
Sim — em 1.000 vídeos, 10.000 vídeos e 100.000 vídeos. Cada post de marco vai manter a mesma metodologia e formato de tabela pra leitoras conseguirem comparar os números diretamente. Assina o RSS do blog do SavedThat ou segue o founder no X pro próximo snapshot.
Posso ver os dados crus?+
Não — vídeos salvos e consultas de busca são dados privados de usuário e não exportáveis. Os números agregados deste post são calculados a partir de contagens anonimizadas; nada na tabela publicada pode ser rastreado até um usuário ou vídeo individual. Se quer verificar a metodologia, cadastra no SavedThat e vai ver os mesmos padrões de consulta na sua própria biblioteca.