Qué guarda realmente la gente: un estudio de datos (2026)
studies
Qué guarda realmente la gente: un estudio de datos (2026)
Analizamos los primeros 119 videos guardados en SavedThat. Mezcla de plataformas, distribución de duración, comportamiento de búsqueda y qué nos dicen los primeros usuarios sobre los flujos de video guardado.
SavedThat team···11 min read
7-day free trial · cancel anytime
La mayoría de los artículos «qué guarda la gente» son vibras. Nosotros sacamos la query real.
Este es un estudio de datos honesto de los primeros 119 videos guardados en SavedThat por 43 usuarios tempranos, y de las 202 búsquedas que esos usuarios han corrido sobre ellos. Muestra pequeña, caveats transparentes. Abajo: qué dicen realmente los números sobre cómo guarda y re-encuentra videos la gente en 2026.
El desglose completo está al final del post. Los tres hallazgos que nos sorprendieron:
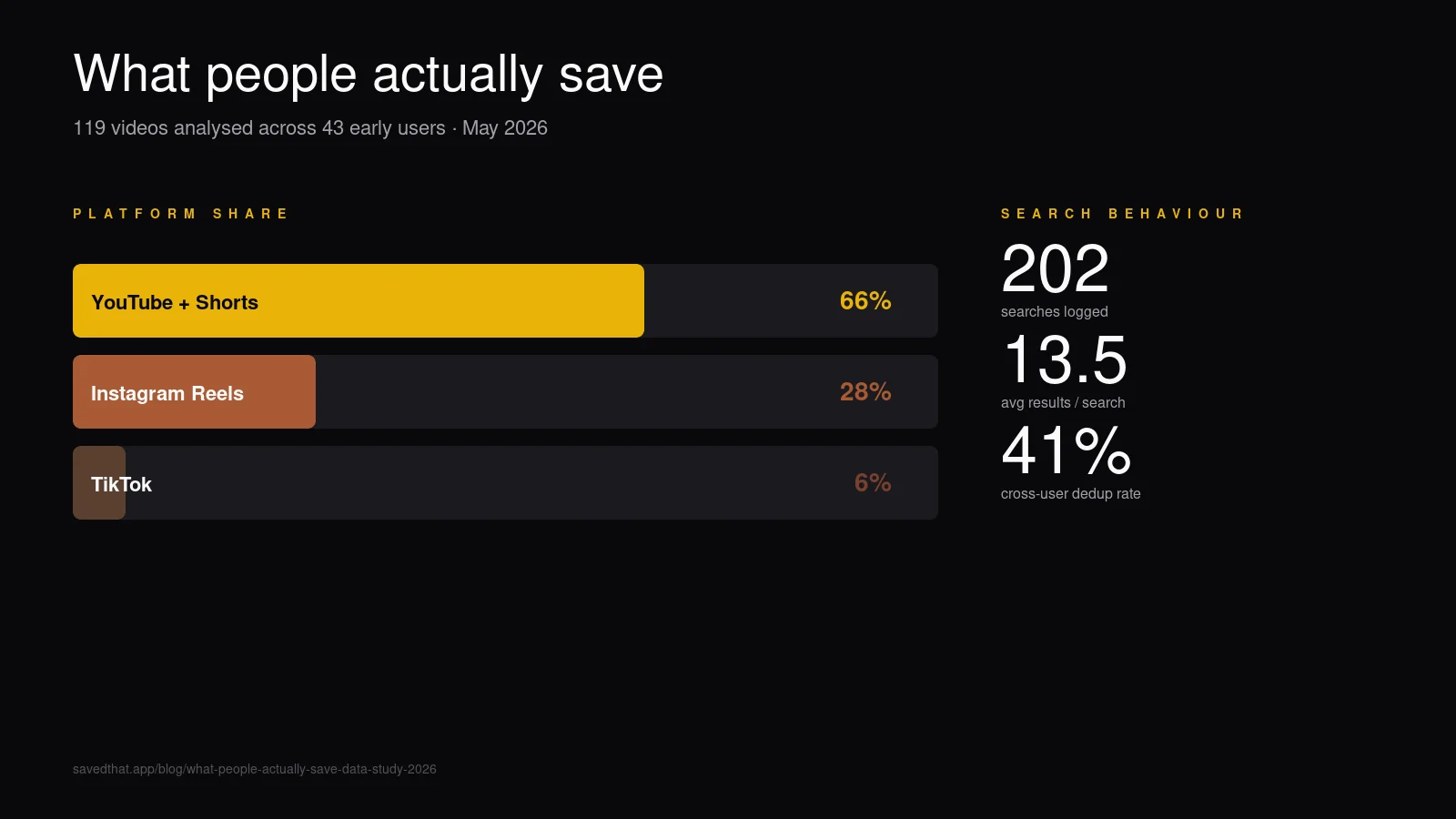
YouTube no domina por número, domina por densidad de contenido. Dos tercios de los videos guardados son de YouTube, pero suman 30+× el volumen de contenido hablado de Instagram + TikTok combinados.
El 16% de las búsquedas devuelve cero resultados. O bien el usuario guardó el video equivocado, o consultó antes de guardar el correcto. Ambos son señales de producto.
La deduplicación entre usuarios entra incluso a esta escala. 158 marcadores apuntan a 112 videos únicos — alrededor de 1 de cada 7 guardados es un duplicado de una transcripción de otro usuario ya indexada.
Videos analizados: 119 (estado ready a 11 de mayo de 2026)
Marcadores: 158 (varios usuarios pueden guardar el mismo video, deduplicado en nuestro almacén de contenido cross-user)
Usuarios únicos: 43 de 43 cuentas registradas
Búsquedas registradas: 202 de 15 usuarios
Pequeño. Caveat por delante. Lo volveremos a correr cuando el corpus llegue a 1.000 y otra vez a 10.000. Los patrones a 100 son ruidosos pero interesantes porque son actuales y están moldeados por quién se registró realmente en un producto en fase temprana.
El dos tercios YouTube confirma lo que asume el marketing de toda herramienta de marcadores: los guardados de video long-form siguen dominando el caso de uso prosumer. Lo que nos sorprendió fue la brecha dentro de YouTube mismo — un promedio de 30 minutos por video significa que nuestros usuarios tempranos guardan podcasts, entrevistas y charlas de conferencia, no Shorts. Compara con la duración media oficial de upload de YouTube — el video mediano en la plataforma es mucho más corto, así que lo que la gente guarda está fuertemente sesgado hacia contenido más largo.
Instagram entra en segundo lugar con 28% — son Reels de formato corto promediando bajo un minuto. Guardar un Reel y guardar un episodio de Lex Fridman de 90 minutos son claramente trabajos distintos aunque ambos acaben en la misma biblioteca.
TikTok va tercero con 6%, mayormente porque la cohorte está sesgada hacia mayores (founders, investigadoras, gente de producto). Esto se reequilibrará rápido conforme la audiencia de SavedThat se amplíe.
Los guardados de YouTube contribuyen 30× más volumen de contenido hablado que Instagram + TikTok combinados. La categoría parece balanceada por número y está fuertemente desequilibrada por lo que de verdad hay dentro de los videos. Esto importa para los flujos de búsqueda en transcripciones: la mayoría de las consultas de búsqueda devuelven hits de YouTube no porque YouTube esté sobrerrepresentado en los guardados, sino porque los videos de YouTube contienen vastamente más texto que matchear.
Los 119 videos se ordenan en dos jorobas claras con una brecha:
Bucket de duración
Videos
% del total
Menos de 1 minuto
38
32%
1-10 minutos
28
24%
10-30 minutos
23
19%
30-60 minutos
13
11%
Más de 1 hora
11
9%
La joroba de 32% menos-de-un-minuto son abrumadoramente Reels y TikToks — guardados rápidos de recetas, demos, bromas. Las jorobas superiores 19% + 11% + 9% (43 videos, 36%) son contenido long-form de YouTube donde la densidad de información por video justifica el guardado.
El bucket del medio 1-10 minutos (24%) es el más raro — tutoriales de YouTube, clips cortos de Lex Fridman, highlights de podcast. Aquí es donde el «watch later» históricamente iba a morir porque los videos son demasiado largos para verlos en scroll casual y demasiado cortos para sentir que vale la pena agendarlos. La búsqueda en transcripciones rescata específicamente este bucket: con 5 minutos de video, nunca lo volverías a ver para encontrar una cita, así que la búsqueda por contenido es el único camino de retrieval.
Registramos 202 búsquedas de 15 de los 43 usuarios. Tres números destacan:
Resultados promedio por búsqueda: 13,5. Una densidad razonable — la búsqueda semántica es por defecto demasiado entusiasta; capeamos la lista de resultados en 20 y el promedio se sienta cómodamente por debajo.
Búsquedas con cero resultados: 33 (16%). Una de cada seis búsquedas no devuelve nada.
Usuarios que han buscado / total: 15 / 43 (35%). Solo un tercio de los usuarios registrados ha buscado todavía.
La tasa del 16% de cero resultados es la métrica más interesante. Tres diagnósticos de por qué:
Corpus equivocado. El usuario buscó una cita de un video que aún no había guardado. Común en la primera semana de uso. El arreglo es del lado del producto: mostrar un empty state «guarda un video primero» cuando un usuario con menos de 3 guardados consulta.
Fallo semántico. El idioma de la consulta estaba demasiado lejos del idioma de la transcripción y la reciprocal rank fusion no salvó la brecha. Lo vemos sobre todo cuando los usuarios consultan en ruso contra una biblioteca totalmente en inglés.
Transcripciones genuinamente malas. Un puñado de videos con auto-subtítulos que no cubrían bien el contenido hablado. La búsqueda no puede encontrar lo que no se indexó.
Estas tres causas se reparten aproximadamente parejas en la revisión manual que hicimos sobre 20 búsquedas con cero resultados. Cada una es un fix de producto; ninguna es un fix del motor de búsqueda.
La tasa de engagement de búsqueda del 35% es honesta y probablemente típica para una herramienta cuyo valor se acumula con el tamaño de la biblioteca — con menos de 5 guardados por usuario, no hay nada útil para buscar. La volveremos a correr una vez que las cuentas crucen los 20 guardados de media para ver si el engagement converge.
158 marcadores contra 112 piezas únicas de contenido significa que aproximadamente el 41% de los usuarios al menos una vez guardó un video que alguien ya había guardado. El video individual más guardado tiene 11 marcadores entre usuarios. Marcadores promedio por pieza de contenido: 1,41.
Esta es una señal económica directa. Cada guardado duplicado es un fetch de transcripción + coste de embedding de OpenAI que no pagamos (Instagram/TikTok se pagan vía Supadata; YouTube es gratis pero facturable en cómputo). Con tasa de hit de dedup del 41% en un corpus de 43 usuarios, el almacén de contenido cross-user ya está ahorrando dinero real. A 1.000 usuarios esperaríamos que la tasa repte hacia el 70%+ — la mayoría de los videos populares convergen.
La implicación de producto: cuando un usuario nuevo guarda un video popular, aterriza en su biblioteca en menos de un segundo con cero coste de créditos, porque la transcripción y los embeddings ya existen. Esa experiencia es un foso — los competidores con almacenes de contenido por-usuario no pueden igualarlo.
La búsqueda en transcripciones es una funcionalidad de video long-form. La brecha de 30× en densidad de contenido entre YouTube y formato corto significa que el peso técnico está en el lado long-form. Las transcripciones de Reels y TikToks son baratas de obtener y buscar; las de YouTube son donde el trabajo de volumen de índice y calidad de retrieval rinde frutos.
El bucket de duración media no tiene dueño. Los videos de 1-10 minutos son el 24% de los guardados y son los peor servidos por las herramientas existentes. El «Watch Later» nativo de YouTube los trata como videos de 60 minutos (scroll para adelante). Las herramientas de formato corto (Glasp) los tratan como videos de 60 segundos (resaltar momentos específicos). Ninguna encaja. Una herramienta de búsqueda en transcripciones que muestre bien el bucket de 1-10 minutos gana este segmento, y casi nadie está optimizando para él.
La dedup cross-user está infra-marketeada. Toda herramienta de búsqueda en transcripciones excepto SavedThat trata la biblioteca de cada usuario como su propia base de datos. A 100 usuarios eso no importa. A 10.000 usuarios es la diferencia entre un margen sostenible y quemar crédito de OpenAI en contenido duplicado. Esperamos que el resto de la categoría copie esto en 12 meses.
Este estudio entero está pensado para ser re-ejecutable. Publicaremos actualizaciones en tres hitos:
1.000 videos analizados. Probablemente H2 2026. Esperamos que la mezcla de plataformas se aplane (TikTok subiendo, YouTube cediendo cuota) y que la tasa de dedup salte.
10.000 videos analizados. Probablemente 2027. La bimodalidad de duración debería afilarse y la tasa de búsquedas con cero resultados debería caer conforme la densidad de contenido alcance la amplitud de las consultas.
100.000 videos analizados. Algún día. Aún no estamos ahí.
Si quieres estar en la próxima foto, la biblioteca en la que guardes es la que contamos. Mira pricing o empieza gratis.
Todo lo demás de este post deriva de esta tabla. La publicamos para que cualquier afirmación de arriba sea verificable contra la fuente.
Métrica
Valor
Total de videos con `status=ready`
119
Total de marcadores de usuario (filas videos.videos)
158
Contenido único (videos.video_content_id distinct)
112
Usuarios registrados
43
Usuarios que han buscado al menos una vez
15
Total de búsquedas registradas
202
Resultados promedio por búsqueda
13,5
Búsquedas con cero resultados
33 (16%)
YouTube + Shorts (ready)
79
Reels de Instagram (ready)
Foto tomada: 11 de mayo de 2026.
Frequently asked questions (2026)
¿119 videos son suficientes para sacar conclusiones?+
No — por eso esto se enmarca como una foto, no un estudio. Los patrones a 100 videos son direccionalmente interesantes pero estadísticamente delgados. Publicamos la metodología y los números exactos para que la próxima foto a 1.000 y 10.000 sea comparable, no para que nadie que lea esto tome decisiones de negocio basadas en una muestra de 119 filas.
¿Se excluyó a algún usuario de los datos?+
Se excluyeron tres filas de video_content en estado `failed` (el fetch de transcripción erroró más allá del límite de reintentos). Los 43 usuarios registrados están incluidos independientemente de su número de guardados, incluidos los 28 usuarios que aún no han buscado. No excluimos ninguna demografía de usuario — la foto refleja a todo el que se había registrado a 11 de mayo de 2026.
¿Cómo se calculó el «volumen de contenido hablado»?+
Conteo de videos por plataforma multiplicado por la duración media en segundos. Esto aproxima el contenido hablado total porque el conteo de palabras de transcripción correlaciona linealmente con la duración para la mayoría del habla. No contamos segmentos silenciosos, música o contenido visual — solo la duración portadora de habla.
¿Por qué los marcadores promedio por contenido (1,41) son tan bajos?+
La dedup cross-user se acumula con el tamaño de la cohorte. A 43 usuarios muestreados desde un lanzamiento temprano de producto, la mayoría de los videos siguen teniendo solo un marcador. Conforme los usuarios registrados crecen, los videos más populares acumulan marcadores más rápido de lo que se guardan videos nuevos, y el promedio sube. Pocket llegó a un promedio de 5-7× marcadores por URL a escala; esperamos trayectoria similar.
33
TikTok (ready)
7
Duración media YouTube
1.810 seg (30:10)
Duración media Reel
56 seg
Duración media TikTok
26 seg
Video individual más marcado
11 usuarios
Marcadores promedio por pieza de contenido
1,41
Tasa de hit de dedup cross-user
~41%
¿Vais a re-correr este estudio a escala?+
Sí — a 1.000 videos, 10.000 videos y 100.000 videos. Cada post de hito mantendrá la misma metodología y formato de tabla para que las lectoras puedan diferenciar los números directamente. Suscríbete al RSS del blog de SavedThat o sigue al founder en X para la próxima foto.
¿Puedo ver los datos crudos?+
No — los videos guardados y las consultas de búsqueda son datos privados de usuario y no exportables. Los números agregados de este post se computan desde conteos anonimizados; nada en la tabla publicada puede rastrearse a ningún usuario o video individual. Si quieres verificar la metodología, regístrate en SavedThat y verás los mismos patrones de consulta en tu propia biblioteca.