Ce que les gens enregistrent vraiment : une étude de données (2026)
studies
Ce que les gens enregistrent vraiment : une étude de données (2026)
On a analysé les 119 premières vidéos enregistrées sur SavedThat. Mix de plateformes, distribution de durée, comportement de recherche et ce que les premiers utilisateurs nous disent sur les workflows de vidéo enregistrée.
SavedThat team···12 min read
7-day free trial · cancel anytime
La plupart des articles « ce que les gens enregistrent » sont des vibes. Nous, on a tiré la vraie requête.
Voici une étude de données honnête des 119 premières vidéos enregistrées sur SavedThat par 43 utilisateurs early, et des 202 recherches que ces utilisateurs ont lancées dessus. Petit échantillon, caveats transparents. En dessous : ce que les chiffres disent vraiment sur la manière dont les gens enregistrent et retrouvent des vidéos en 2026.
Le décorticage complet est en bas du post. Les trois trouvailles qui nous ont surpris :
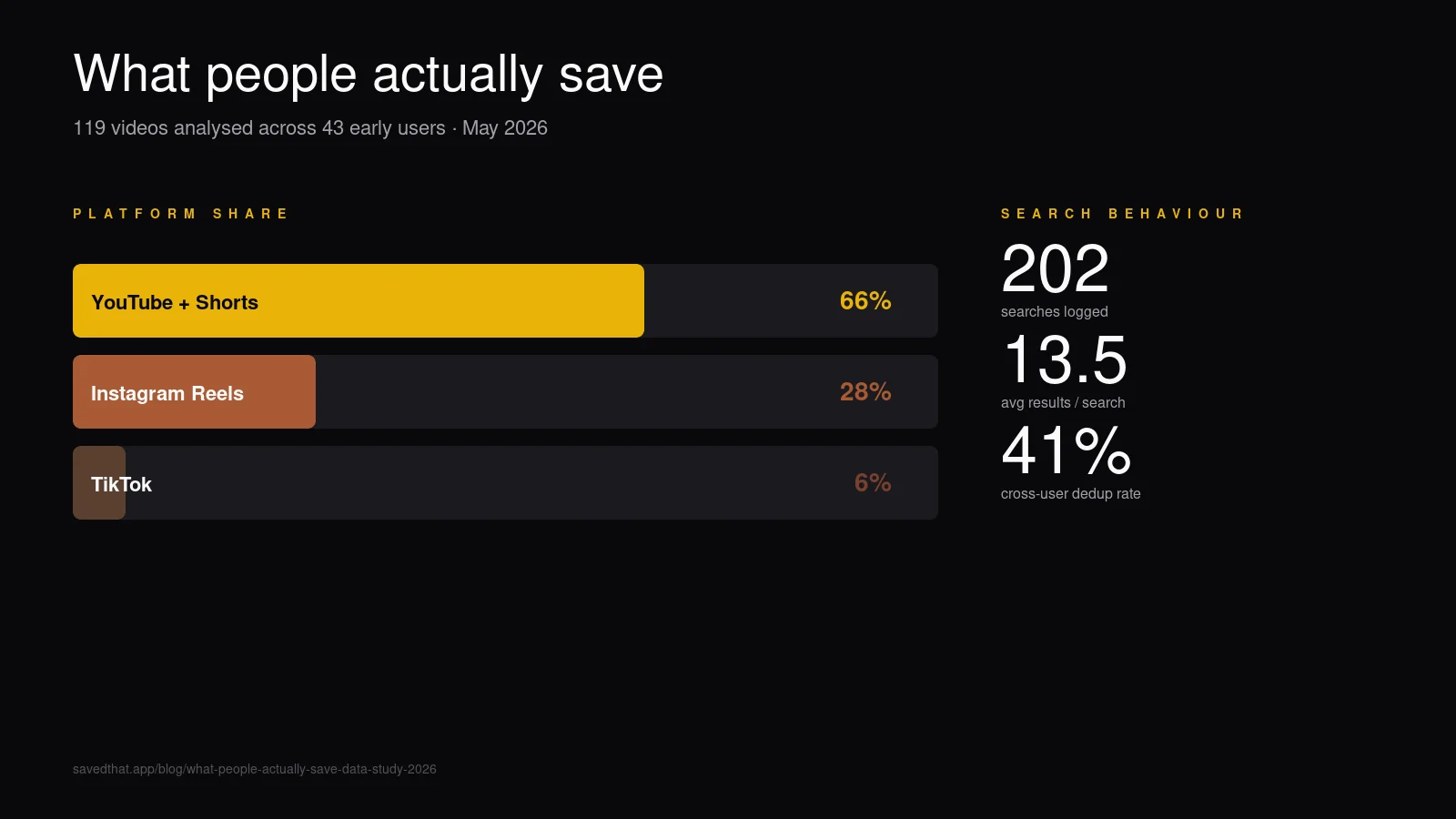
YouTube n'est pas dominant en nombre, il est dominant en densité de contenu. Deux tiers des vidéos enregistrées sont YouTube, mais elles représentent 30+× le volume de contenu parlé d'Instagram + TikTok combinés.
16% des recherches renvoient zéro résultat. Soit l'utilisateur a enregistré la mauvaise vidéo, soit il a cherché avant d'avoir enregistré la bonne. Les deux sont des signaux produit.
La déduplication cross-user opère même à cette échelle. 158 favoris pointent vers 112 vidéos uniques — environ 1 sur 7 enregistrements est un duplicata d'une transcription déjà indexée par quelqu'un.
Vidéos analysées : 119 (statut ready au 11 mai 2026)
Favoris : 158 (plusieurs utilisateurs peuvent enregistrer la même vidéo, dédupliquée dans notre store de contenu cross-user)
Utilisateurs uniques : 43 sur 43 comptes inscrits
Recherches loguées : 202 par 15 utilisateurs
Petit. Caveat assumé d'entrée. On rejouera quand le corpus atteint 1 000 et encore à 10 000. Les patterns à 100 sont bruyants mais intéressants parce qu'ils sont actuels et formés par qui s'est vraiment inscrit sur un produit early-stage.
Deux tiers YouTube confirme ce que présuppose le marketing de chaque outil de favoris : les enregistrements de vidéo long-format dominent toujours le cas prosumer. Ce qui nous a surpris, c'est l'écart à l'intérieur même de YouTube — 30 minutes en moyenne signifient que nos early users enregistrent des podcasts, des interviews et des talks de conférence, pas des Shorts. Compare avec la durée médiane officielle d'upload YouTube — la vidéo médiane sur la plateforme est bien plus courte, donc ce que les gens enregistrent est nettement biaisé vers le contenu plus long.
Instagram arrive second à 28% — ce sont des Reels format court à moins d'une minute. Enregistrer un Reel et enregistrer un épisode Lex Fridman de 90 minutes sont clairement des jobs différents même si les deux finissent dans la même bibliothèque.
TikTok est troisième à 6%, surtout parce que la cohorte penche plus âgée (founders, chercheurs, gens produit). Ça va se rééquilibrer vite à mesure que l'audience SavedThat s'élargit.
Les enregistrements YouTube contribuent 30× plus de volume de contenu parlé qu'Instagram + TikTok combinés. La catégorie semble équilibrée en comptes et est fortement déséquilibrée par ce qu'il y a vraiment dedans. Ça compte pour les workflows de recherche dans les transcriptions : la plupart des requêtes renvoient des hits YouTube non parce que YouTube est surreprésenté dans les enregistrements, mais parce que les vidéos YouTube contiennent vastement plus de texte à matcher.
Les 119 vidéos se trient en deux bosses claires avec un creux :
Tranche de durée
Vidéos
% du total
Moins d'1 minute
38
32%
1-10 minutes
28
24%
10-30 minutes
23
19%
30-60 minutes
13
11%
Plus d'1 heure
11
9%
La bosse 32% moins-d'une-minute est massivement des Reels et TikToks — enregistrements rapides de recettes, démos, blagues. Les bosses hautes 19% + 11% + 9% (43 vidéos, 36%) sont du contenu YouTube long-format où la densité d'info par vidéo justifie l'enregistrement.
La tranche du milieu 1-10 minutes (24%) est la plus bizarre — tutos YouTube, clips Lex Fridman courts, highlights de podcasts. C'est là que « watch later » a historiquement été mourir parce que les vidéos sont trop longues pour du scroll-watching décontracté et trop courtes pour valoir le coup de les planifier. La recherche dans les transcriptions sauve cette tranche spécifiquement : à 5 minutes par vidéo, tu ne re-regarderais jamais pour trouver une citation, donc la recherche-par-contenu est le seul chemin de retrieval.
On a logué 202 recherches par 15 des 43 utilisateurs. Trois chiffres sautent aux yeux :
Résultats moyens par recherche : 13,5. Une densité raisonnable — la recherche sémantique est over-eager par défaut ; on plafonne la liste de résultats à 20 et la moyenne se pose confortablement en dessous.
Recherches zéro-résultat : 33 (16%). Une recherche sur six ne renvoie rien.
Utilisateurs qui ont cherché / total : 15 / 43 (35%). Seul un tiers des utilisateurs inscrits ont cherché jusqu'à présent.
Le taux 16% zéro-résultat est la métrique la plus intéressante. Trois diagnostics du pourquoi :
Mauvais corpus. L'utilisateur a cherché une citation d'une vidéo qu'il n'avait pas vraiment enregistrée. Courant la première semaine d'usage. Le fix est côté produit : faire remonter un empty state « enregistre une vidéo d'abord » quand un utilisateur avec moins de 3 enregistrements cherche.
Manqué sémantique. La langue de la requête était trop loin de la langue de la transcription et la reciprocal rank fusion n'a pas franchi le gap. On voit ça surtout quand des utilisateurs cherchent en russe contre une bibliothèque entièrement anglaise.
Transcriptions vraiment mauvaises. Une poignée de vidéos avec des auto-sous-titres qui n'ont pas bien couvert le contenu parlé. La recherche ne peut pas trouver ce qui n'a pas été indexé.
Ces trois causes se répartissent à peu près également dans la revue manuelle qu'on a faite sur 20 recherches zéro-résultat. Chacune est un fix produit ; aucune n'est un fix moteur de recherche.
Le taux d'engagement recherche à 35% est honnête et probablement typique pour un outil dont la valeur s'accumule avec la taille de la bibliothèque — à moins de 5 enregistrements par utilisateur, il n'y a rien d'utile à chercher dedans. On rejouera ça une fois que les comptes franchissent 20 enregistrements en moyenne pour voir si l'engagement converge.
158 favoris contre 112 pièces de contenu uniques signifie qu'environ 41% des utilisateurs ont au moins une fois enregistré une vidéo que quelqu'un d'autre avait déjà enregistrée. La vidéo unique la plus enregistrée a 11 favoris entre utilisateurs. Favoris moyens par pièce de contenu : 1,41.
C'est un signal économique direct. Chaque enregistrement duplicata est un fetch de transcription + coût d'embedding OpenAI qu'on ne paie pas (Instagram/TikTok sont payés via Supadata ; YouTube est gratuit mais compute-billable). À 41% de taux de hit dedup sur un corpus de 43 utilisateurs, le store de contenu cross-user économise déjà du vrai argent. À 1 000 utilisateurs, on s'attendrait à ce que le taux rampe vers 70%+ — la plupart des vidéos populaires convergent.
L'implication produit : quand un nouvel utilisateur enregistre une vidéo populaire, elle atterrit dans sa bibliothèque en moins d'une seconde avec zéro coût de crédit, parce que la transcription et les embeddings existent déjà. Cette expérience est un moat — les concurrents avec des stores de contenu par-utilisateur ne peuvent pas matcher ça.
La recherche dans les transcriptions est une fonctionnalité de vidéo long-format. L'écart 30× de densité de contenu entre YouTube et format court signifie que le gros du boulot technique est du côté long-format. Les transcriptions Reels et TikTok sont peu chères à récupérer et chercher ; les transcriptions YouTube sont là où le volume d'index et la qualité du retrieval paient.
La tranche de durée moyenne est sans propriétaire. Les vidéos 1-10 minutes font 24% des enregistrements et sont les moins bien servies par les outils existants. Le « Watch Later » natif de YouTube les traite comme des vidéos de 60 minutes (scroll devant). Les outils format court (Glasp) les traitent comme des vidéos de 60 secondes (surligner des moments spécifiques). Ni l'un ni l'autre ne colle. Un outil de recherche dans les transcriptions qui sert bien la tranche 1-10 minutes gagne ce segment, et presque personne n'optimise pour.
La dédup cross-user est sous-marketée. Chaque outil de recherche dans les transcriptions sauf SavedThat traite la bibliothèque de chaque utilisateur comme sa propre base. À 100 utilisateurs ça ne compte pas. À 10 000 utilisateurs, c'est la différence entre une marge soutenable et brûler des crédits OpenAI sur du contenu duplicata. On s'attend à ce que le reste de la catégorie copie ça dans les 12 mois.
Cette étude entière est faite pour être rejouable. On publiera des mises à jour à trois jalons :
1 000 vidéos analysées. Probablement S2 2026. On s'attend à ce que le mix de plateformes s'aplatisse (TikTok grimpant, YouTube cédant de la part), et que le taux de dédup saute.
10 000 vidéos analysées. Probablement 2027. La bimodalité de durée devrait s'affûter, et le taux de recherches zéro-résultat devrait baisser à mesure que la densité de contenu rattrape l'amplitude des requêtes.
100 000 vidéos analysées. Un jour. On n'y est pas encore.
Si tu veux être dans le prochain snapshot, la bibliothèque dans laquelle tu enregistres est celle qu'on compte. Voir pricing ou commencer gratuitement.
Tout le reste de ce post dérive de ce tableau. On le publie pour que toute affirmation au-dessus soit vérifiable contre la source.
Métrique
Valeur
Total vidéos avec `status=ready`
119
Total favoris utilisateurs (lignes videos.videos)
158
Contenu unique (videos.video_content_id distinct)
112
Utilisateurs inscrits
43
Utilisateurs ayant cherché au moins une fois
15
Total recherches loguées
202
Résultats moyens par recherche
13,5
Recherches zéro-résultat
33 (16%)
YouTube + Shorts (ready)
79
Reels Instagram (ready)
Snapshot pris : 11 mai 2026.
Frequently asked questions (2026)
119 vidéos, c'est assez pour en tirer des conclusions ?+
Non — c'est pourquoi c'est cadré comme un snapshot, pas une étude. Les patterns à 100 vidéos sont directionnellement intéressants mais statistiquement minces. On publie la méthodologie et les chiffres exacts pour que le prochain snapshot à 1 000 et 10 000 soit comparable, pas pour que quiconque lisant ça doive prendre des décisions business sur un échantillon de 119 lignes.
Des utilisateurs ont-ils été exclus des données ?+
Trois lignes video_content en statut `failed` ont été exclues (le fetch de transcription a erroré au-delà de la limite de retries). Les 43 utilisateurs inscrits sont inclus quel que soit leur nombre d'enregistrements, y compris les 28 utilisateurs qui n'ont pas encore cherché. On n'a exclu aucune démographie utilisateur — le snapshot reflète tout le monde inscrit au 11 mai 2026.
Comment a été calculé le « volume de contenu parlé » ?+
Nombre de vidéos par plateforme multiplié par la durée moyenne en secondes. Ça approxime le contenu parlé total parce que le nombre de mots de la transcription corrèle linéairement avec la durée pour la plupart de la parole. On ne compte pas les segments silencieux, la musique ou le contenu visuel — seulement la durée porteuse de parole.
Pourquoi le nombre moyen de favoris par contenu (1,41) est-il si bas ?+
La dédup cross-user se compose avec la taille de cohorte. À 43 utilisateurs échantillonnés depuis un lancement produit early, la plupart des vidéos n'ont encore qu'un seul favori. À mesure que les utilisateurs inscrits grandissent, les vidéos les plus populaires accumulent des favoris plus vite que les nouvelles vidéos ne sont enregistrées, et la moyenne grimpe. Pocket atteignait 5-7× favoris moyens par URL à l'échelle ; on s'attend à une trajectoire similaire.
33
TikTok (ready)
7
Durée moyenne YouTube
1 810 sec (30:10)
Durée moyenne Reel
56 sec
Durée moyenne TikTok
26 sec
Vidéo unique la plus enregistrée
11 utilisateurs
Favoris moyens par pièce de contenu
1,41
Taux de hit dédup cross-user
~41%
Vous allez rejouer cette étude à l'échelle ?+
Oui — à 1 000 vidéos, 10 000 vidéos et 100 000 vidéos. Chaque post de jalon gardera la même méthodologie et le même format de tableau pour que les lectrices puissent diffuser les chiffres directement. Abonne-toi au RSS du blog SavedThat ou suis le founder sur X pour le prochain snapshot.
Je peux voir les données brutes ?+
Non — les vidéos enregistrées et les requêtes de recherche sont des données privées d'utilisateur et non exportables. Les chiffres agrégés de ce post sont calculés à partir de comptes anonymisés ; rien dans le tableau publié ne peut être tracé vers un utilisateur ou une vidéo individuels. Si tu veux vérifier la méthodologie, inscris-toi sur SavedThat et tu verras les mêmes patterns de requête dans ta propre bibliothèque.