Что люди реально сохраняют: data-исследование (2026)
studies
Что люди реально сохраняют: data-исследование (2026)
Проанализировали первые 119 видео сохранённых на SavedThat. Микс платформ, распределение длительности, поведение в поиске и что ранние юзеры рассказывают о workflow сохранёнок.
SavedThat team··9 min read
7 дней бесплатно · отмена в любой момент
Большинство статей «что люди сохраняют» — это вайбы. Мы вытащили реальный SQL-запрос.
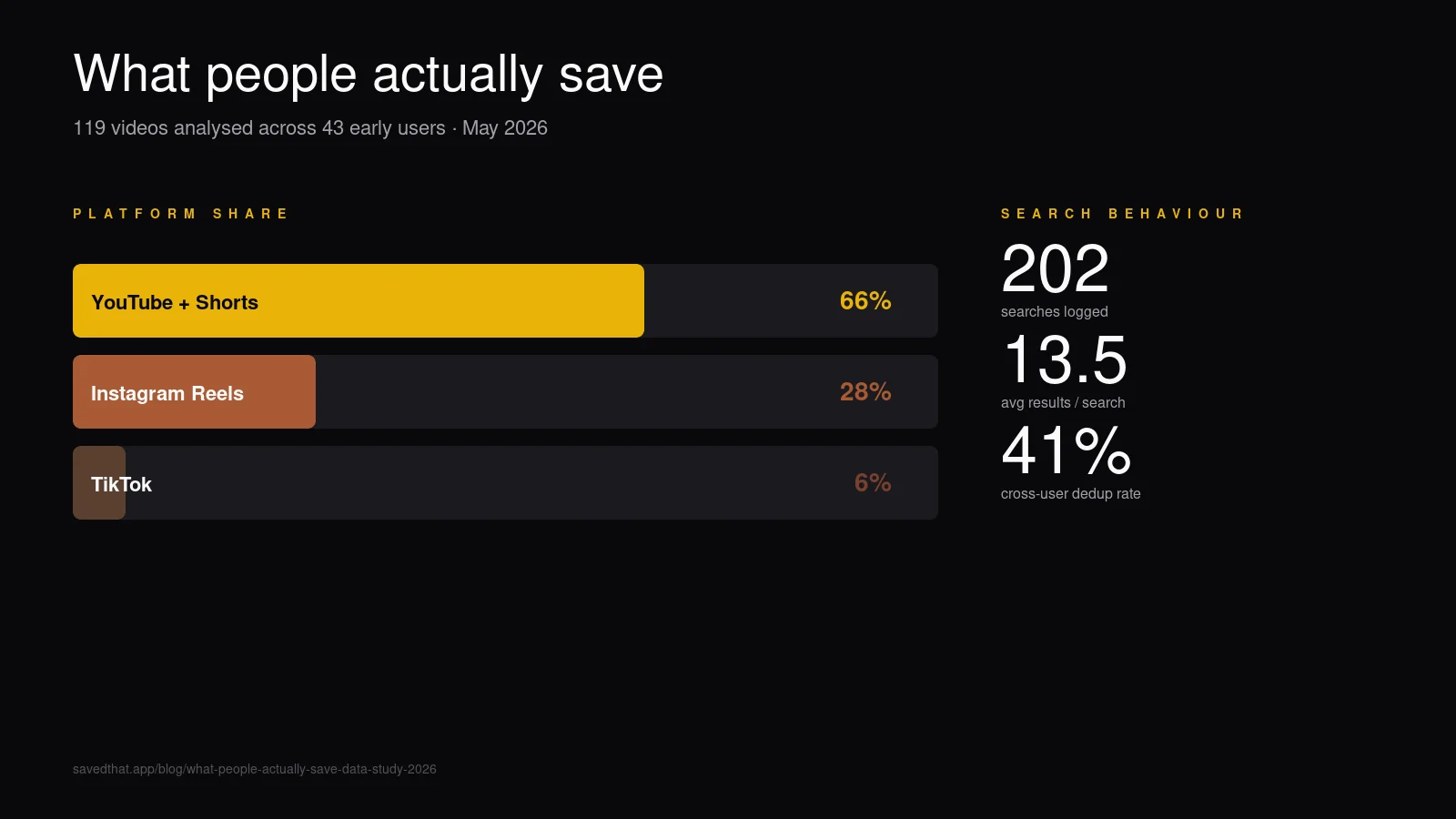
Это честное data-исследование первых 119 видео сохранённых на SavedThat 43 ранними юзерами, и 202 поисков которые эти юзеры запустили по ним. Маленький sample, прозрачные оговорки. Дальше: что цифры реально говорят о том как люди сохраняют и пере-находят видео в 2026-м.
Полный разбор в конце поста. Три находки которые нас удивили:
YouTube доминирует не по количеству, а по плотности контента. Две трети сохранённых видео — YouTube, но они дают 30+× произнесённого контента по объёму чем Instagram + TikTok вместе.
16% поисков возвращают zero results. Либо юзер сохранил не то видео, либо запросил до того как сохранил нужное. Оба — продуктовые сигналы.
Кросс-юзерская дедупликация срабатывает даже на этом масштабе. 158 закладок указывают на 112 уникальных видео — примерно 1 из 7 сохранений это дубликат уже-индексированного транскрипта.
Видео проанализировано: 119 (статус ready на 11 мая 2026)
Закладок: 158 (несколько юзеров могут сохранить одно видео, дедупликация в кросс-юзерском контент-сторе)
Уникальных юзеров: 43 из 43 зарегистрированных аккаунтов
Поисков залогировано: 202 от 15 юзеров
Маленько. Оговорка вынесена вперёд. Перезапустим когда корпус достигнет 1000 и снова на 10 000. Паттерны на 100 шумные но интересные потому что они текущие и сформированы тем кто реально регистрировался на early-stage продукте.
Две трети YouTube подтверждает то что предполагает маркетинг каждого bookmark-инструмента: long-form video saves всё ещё доминируют в use case продвинутого юзера. Удивило нас разрыв внутри самого YouTube — средние 30-минутные видео означают что наши ранние юзеры сохраняют подкасты, интервью и conference talks, не Shorts. Сравни с официальной медианной длительностью загрузок на YouTube — медианное видео на платформе сильно короче, так что что люди сохраняют резко смещено к длинному контенту.
Instagram идёт вторым на 28% — это short-form Reels со средней длительностью под минуту. Сохранять Reel и сохранять 90-минутный эпизод Lex Fridman — это явно разные job'ы, даже хотя оба попадают в одну библиотеку.
TikTok третий на 6%, в основном потому что когорта смещена к старшим (фаундеры, исследователи, product-люди). Это быстро ребалансируется по мере расширения аудитории SavedThat.
YouTube: 79 видео × 1810 сек в среднем = 143 000 секунд произнесённого
Instagram: 33 видео × 56 сек = 1850 секунд произнесённого
TikTok: 7 видео × 26 сек = 180 секунд произнесённого
YouTube-сохранения дают в 30× больше произнесённого контента по объёму чем Instagram + TikTok вместе. Категория выглядит сбалансированной по числу и сильно перекошенной по тому что реально внутри видео. Это важно для transcript-search workflow: большинство поисковых запросов возвращают YouTube-хиты не потому что YouTube перепредставлен в сохранениях, а потому что YouTube-видео содержат гораздо больше текста для матчинга.
119 видео сортируются на две явные горки с провалом:
Бакет длительности
Видео
% от общего
Меньше 1 минуты
38
32%
1–10 минут
28
24%
10–30 минут
23
19%
30–60 минут
13
11%
Больше 1 часа
11
9%
Горка «меньше минуты» на 32% — это в подавляющем большинстве Reels и TikTok'и, быстрые сохранения рецептов, демо, шуток. Верхние горки 19% + 11% + 9% (43 видео, 36%) — это long-form YouTube-контент где плотность информации per-видео оправдывает сохранение.
Средний bucket 1–10 минут (24%) — самый странный — YouTube-туториалы, короткие Lex-Fridman-клипы, podcast-highlights. Это где «watch later» исторически умирал потому что видео слишком длинные для casual scroll-watching и слишком короткие чтобы планировать. Transcript search спасает именно этот bucket: на 5 минутах видео ты никогда не будешь пересматривать чтобы найти цитату, так что search-by-content — единственный retrieval-путь.
Залогировали 202 поиска от 15 из 43 юзеров. Три числа выделяются:
В среднем результатов на запрос: 13.5. Разумная плотность — семантический поиск over-eager by default; мы капаем result list на 20, и среднее комфортно ниже.
Zero-result поисков: 33 (16%). Один из шести запросов не возвращает ничего.
Юзеры которые искали / всего: 15 / 43 (35%). Только треть зарегистрированных юзеров поискала хотя бы раз.
16% zero-result rate — самая интересная метрика. Три диагностики почему:
Не тот корпус. Юзер искал цитату из видео которое не сохранил. Часто в первую неделю использования. Фикс — продуктовый: показать empty state «сохрани сначала» когда юзер с меньше 3 сохранений запрашивает.
Семантический промах. Язык запроса слишком далеко от языка транскрипта, reciprocal rank fusion не закрыл разрыв. Это видим больше всего когда юзеры запрашивают на русском против полностью английской библиотеки.
Реально плохие транскрипты. Горстка видео с авто-субтитрами которые плохо покрыли произнесённый контент. Поиск не может найти то что не было проиндексировано.
Эти три причины примерно равномерно делятся в ручном ревью 20 zero-result поисков которое мы провели. Каждая — продуктовый фикс; никакой — фикс search-движка.
35% search-engagement rate честный и наверное типичный для инструмента чья ценность компаундит с размером библиотеки — при меньше 5 сохранений на юзера нечего искать. Перезапустим когда аккаунты пересекут в среднем 20 сохранений чтобы посмотреть сходится ли engagement.
158 закладок против 112 уникальных частей контента означают что около 41% юзеров хотя бы один раз сохранили видео которое уже кто-то сохранил. Самое-сохраняемое одиночное видео имеет 11 закладок поверх юзеров. Среднее число закладок на часть контента: 1.41.
Это прямой экономический сигнал. Каждое дублирующее сохранение — это transcript fetch + стоимость OpenAI-эмбеддинга которые мы не платим (Instagram/TikTok платно через Supadata; YouTube бесплатно, но compute-billable). На 41% dedup hit rate в 43-юзерском корпусе кросс-юзерский контент-стор уже экономит реальные деньги. На 1000 юзеров мы бы ждали что rate ползёт к 70%+ — самые популярные видео сходятся.
Продуктовая импликация: когда новый юзер сохраняет популярное видео — оно приземляется в библиотеку меньше чем за секунду без credit-стоимости, потому что транскрипт и эмбеддинги уже существуют. Этот опыт — moat; конкуренты с per-user контент-сторами этого не сматчат.
Transcript search — это long-form-видео-фича. 30× разрыв content-density между YouTube и short-form означает что техническая тяжёлая работа — на long-form стороне. Транскрипты Reels и TikTok дёшево фетчить и искать; YouTube-транскрипты — там где работа на index-volume и retrieval-quality окупается.
Middle-duration bucket — без хозяина. 1–10 минутные видео составляют 24% сохранений и хуже всего обслуживаются существующими инструментами. Нативный YouTube «Watch Later» обращается с ними как с 60-минутными (скролл-мимо). Short-form инструменты (Glasp) — как с 60-секундными (хайлайт конкретных моментов). Никто не подходит. Transcript-search инструмент который хорошо поднимает 1–10 минутный bucket выигрывает этот сегмент, и почти никто его не оптимизирует.
Кросс-юзерский dedup — недопромаркетирован. Каждый transcript-search инструмент кроме SavedThat обращается с библиотекой каждого юзера как с собственной базой. На 100 юзерах не важно. На 10 000 — это разница между устойчивой маржой и сжиганием OpenAI-кредита на дублирующий контент. Ждём что остальная категория скопирует это в 12 месяцев.
Это исследование задумано как re-runnable. Опубликуем апдейты на трёх milestones:
1000 видео проанализировано. Вероятно H2 2026. Ждём что микс платформ выровняется (TikTok ползёт вверх, YouTube уступает долю), а dedup-rate скакнёт.
10 000 видео проанализировано. Вероятно 2027. Бимодальность длительности должна обостриться, а zero-result rate упасть когда плотность контента догонит ширину запросов.
100 000 видео проанализировано. Когда-нибудь. Мы ещё не там.
Если хочешь быть в следующем snapshot'е — библиотека в которую ты сохраняешь это та что мы считаем. См. pricing или start free.
Нет — поэтому это рамлено как snapshot, а не исследование. Паттерны на 100 видео directionally интересные но статистически тонкие. Публикуем методологию и точные числа чтобы следующий snapshot на 1000 и 10 000 был сравним, а не чтобы кто-то читая делал бизнес-решения на 119-строчном sample.
Каких-то юзеров исключали из данных?+
Три video_content-строки в статусе `failed` исключены (transcript fetch ошибся за пределами retry-лимита). Все 43 зарегистрированных юзера включены независимо от их save-count, включая 28 юзеров которые пока не искали. Никаких юзер-демографий не исключали — snapshot отражает каждого кто зарегистрировался на 11 мая 2026.
Как считался «объём произнесённого контента»?+
Количество видео по платформе умноженное на среднюю длительность в секундах. Это аппроксимирует общий произнесённый контент потому что word-count транскрипта линейно коррелирует с длительностью для большинства речи. Не считаем тихие сегменты, музыку или визуальный контент — только speech-bearing длительность.
Почему среднее закладок на контент (1.41) так низко?+
Кросс-юзерский dedup компаундит с размером когорты. На 43 юзерах семплированных с раннего лонча большинство видео всё ещё имеют только одну закладку. По мере роста зарегистрированных юзеров самые-популярные видео накапливают закладки быстрее чем сохраняются новые видео, и среднее лезет вверх. Pocket дошёл до 5–7× среднего закладок на URL на масштабе; ждём похожей траектории.
33
TikTok (ready)
7
Средняя длительность YouTube
1810 сек (30:10)
Средняя длительность Reel
56 сек
Средняя длительность TikTok
26 сек
Самое сохраняемое одиночное видео
11 юзеров
Среднее закладок на часть контента
1.41
Кросс-юзерский dedup hit rate
~41%
Будете перезапускать это исследование на масштабе?+
Да — на 1000 видео, 10 000 и 100 000. Каждый milestone-пост будет держать ту же методологию и формат таблицы чтобы читатели могли diff'ать числа напрямую. Подпишись на RSS блога SavedThat или на фаундера в X для следующего snapshot'а.
Можно посмотреть сырые данные?+
Нет — сохранённые видео и поисковые запросы это приватные user-данные и не экспортируются. Агрегатные числа в этом посте вычислены из анонимизированных счётчиков; ничего в опубликованной таблице нельзя оттрассировать на конкретного юзера или видео. Если хочешь верифицировать методологию — зарегистрируйся в SavedThat и увидишь те же паттерны запросов в своей библиотеке.